
Named Entity Recognition with BERT
Named Entity Recognition with BERT utilizes cutting-edge technology to accurately identify and categorize named entities in textual data. By leveraging BERT's advanced capabilities, this tool streamlines information extraction processes by recognizing entities like names of individuals, organizations, and locations within text, enhancing text analysis efficiency.
![]()
![]()
Named Entity Recognition with BERT
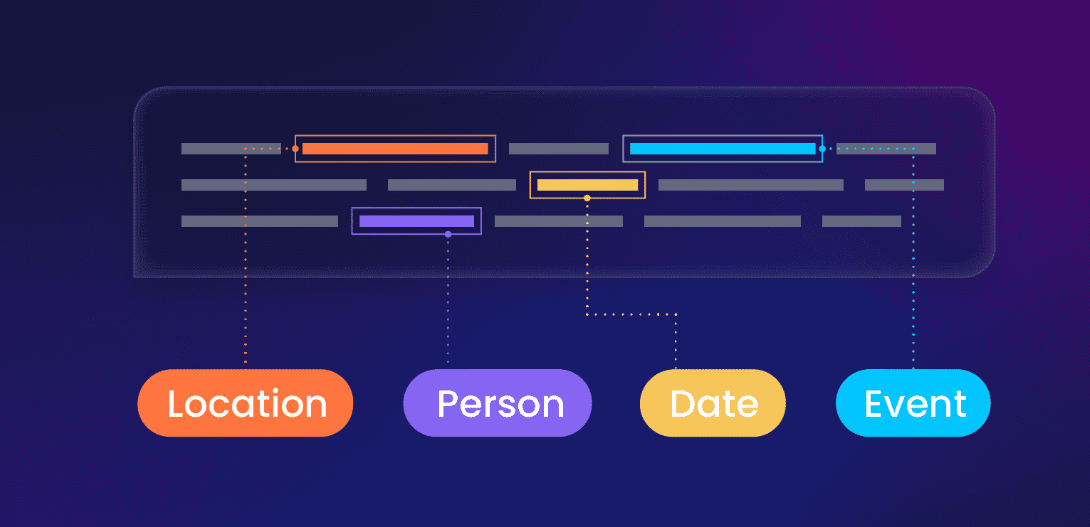
Summary
Introduction
Named Entity Recognition (NER) is a natural language processing (NLP) task that involves identifying and classifying named entities in text. Named entities are specific, identifiable objects, such as names of people, organizations, locations, dates, quantities, or other proper nouns.
The bert-base-NER is a pre-trained BERT model that has been fine-tuned specifically for Named Entity Recognition (NER). It demonstrates exceptional performance and achieves state-of-the-art results in the NER task. The model is capable of identifying four types of entities: locations (LOC), organizations (ORG), persons (PER), and miscellaneous (MISC).
More specifically, this model is based on the bert-base-cased architecture and has undergone fine-tuning using the English version of the widely recognized CoNLL-2003 Named Entity Recognition dataset. This training process has equipped the model with the ability to accurately recognize and classify entities in text, making it suitable for various NER applications.
Parameters
Inputs
input- (text): The input can be a single sentence or a batch of sentences.
Output
output- (text): The output of the model is a sequence of labels or tags that correspond to the named entities present in the input text. Each token in the input sequence is assigned a label indicating whether it belongs to a named entity and, if so, which entity type it represents (e.g., LOC, ORG, PER, MISC).
Examples
| input | output |
|---|---|
| My name is Wolfgang and I live in Berlin |  |
| My name is Clara and I live in Berkeley, California. |  |
Usage for developers
Please find below the details to track the information and access the code for processing the model on our platform.
Requirements
torch
transformers
Code based on AIOZ structure
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
import torch, os
...
def do_ai_task(
input: Union[str, Path],
model_storage_directory: Union[str, Path],
device: Literal["cpu", "cuda", "gpu"] = "cpu",
*args, **kwargs) -> Any:
"""Define AI task: load model, pre-process, post-process, etc ..."""
# Define AI task workflow. Below is an example
device = "cuda" if torch.cuda.is_available() else "cpu"
id = os.path.abspath(model_storage_directory + "/...")
tokenizer = AutoTokenizer.from_pretrained(id)
model = AutoModelForTokenClassification.from_pretrained(id)
nlp = pipeline("ner", model=model, tokenizer=tokenizer, aggregation_strategy="simple", device=device)
with torch.no_grad():
ner_results = nlp(input)
ner_results.insert(0, {'infor': input})
return str(ner_results)
Reference
This repository is based on and inspired by David S. Lim's work. We sincerely appreciate their generosity in sharing the code.
License
We respect and comply with the terms of the author's license cited in the Reference section.
Citation
@article{DBLP:journals/corr/abs-1810-04805,
author = {Jacob Devlin and
Ming{-}Wei Chang and
Kenton Lee and
Kristina Toutanova},
title = {{BERT:} Pre-training of Deep Bidirectional Transformers for Language
Understanding},
journal = {CoRR},
volume = {abs/1810.04805},
year = {2018},
url = {http://arxiv.org/abs/1810.04805},
archivePrefix = {arXiv},
eprint = {1810.04805},
timestamp = {Tue, 30 Oct 2018 20:39:56 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1810-04805.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
@inproceedings{tjong-kim-sang-de-meulder-2003-introduction,
title = "Introduction to the {C}o{NLL}-2003 Shared Task: Language-Independent Named Entity Recognition",
author = "Tjong Kim Sang, Erik F. and
De Meulder, Fien",
booktitle = "Proceedings of the Seventh Conference on Natural Language Learning at {HLT}-{NAACL} 2003",
year = "2003",
url = "https://www.aclweb.org/anthology/W03-0419",
pages = "142--147",
}