
Dense Prediction for Vision Transformers
Dense Prediction for Vision Transformers is a task focused on applying Vision Transformers (ViTs) to dense prediction problems, such as object detection, semantic segmentation, and depth estimation. Unlike traditional image classification tasks, dense prediction involves making predictions for each pixel or region in an image.
![]()
![]()
Dense Prediction for Vision Transformers

Summary
Introduction
The Dense Prediction Transformer (DPT) model has been trained on a dataset of 1.4 million images specifically for the task of monocular depth estimation. It was introduced in the research paper titled Vision Transformers for Dense Prediction by Ranftl et al. in 2021 and was initially made available in the provided repository.
DPT builds upon the Vision Transformer (ViT) as its backbone architecture and extends it with additional components for monocular depth estimation. The model consists of a "neck" and a "head" that are added on top of the ViT backbone.
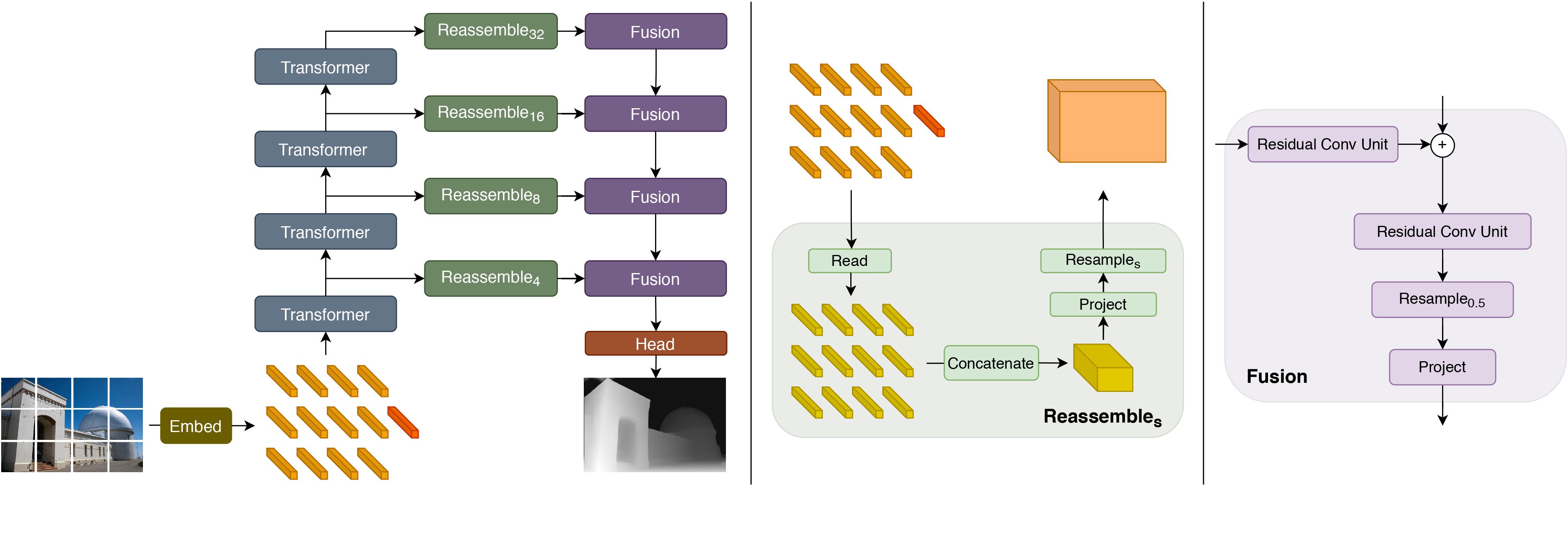
The repository contains the "hybrid" version of the model, as described in the paper. Referred to as DPT-Hybrid, it deviates from the original DPT model by utilizing ViT-hybrid as its backbone architecture and incorporating selected activations from this backbone.
Parameters
Inputs
- input - (image -.png|.jpg|.jpeg): The input of the model is typically an image or a set of images captured by a camera. They can be in different formats and have various dimensions.
Output
- output - (image -.png): The output of the model for depth estimation is a dense depth map. This map represents the estimated depth values for each pixel in the input image(s). It provides information about the relative distance or depth of objects in the scene. The depth map can be visualized as a grayscale image, where darker regions correspond to closer objects and lighter regions represent farther objects.
Examples
| input | output |
|---|---|
 |  |
 |  |
 |  |
Usage for developers
Please find below the details to track the information and access the code for processing the model on our platform.
Requirements
torch
transformers
Pillow
numpy
Code based on AIOZ structure
from PIL import Image
import numpy as np
import torch, os
from transformers import DPTImageProcessor, DPTForDepthEstimation
...
def do_ai_task(
input: Union[str, Path],
model_storage_directory: Union[str, Path],
device: Literal["cpu", "cuda", "gpu"] = "cpu",
*args, **kwargs) -> Any:
model_id = os.path.abspath(model_storage_directory + "...")
image_processor = DPTImageProcessor.from_pretrained(repo_id)
model = DPTForDepthEstimation.from_pretrained(repo_id, low_cpu_mem_usage=True).to(device)
image = Image.open(input).convert('RGB')
# prepare image for the model
inputs = image_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs.to(device))
predicted_depth = outputs.predicted_depth
# interpolate to original size
prediction = torch.nn.functional.interpolate(
predicted_depth.unsqueeze(1),
size=image.size[::-1],
mode="bicubic",
align_corners=False,
)
output = prediction.squeeze().cpu().numpy()
formatted = (output * 255 / np.max(output)).astype("uint8")
depth = Image.fromarray(formatted)
depth.save("output.png")
output = open("output.png", "rb") # io.BufferedReader
return output
Reference
This repository is based on and inspired by Intel's work. We sincerely appreciate their generosity in sharing the code.
License
We respect and comply with the terms of the author's license cited in the Reference section.
Citation
@article{DBLP:journals/corr/abs-2103-13413,
author = {Ren{\'{e}} Ranftl and
Alexey Bochkovskiy and
Vladlen Koltun},
title = {Vision Transformers for Dense Prediction},
journal = {CoRR},
volume = {abs/2103.13413},
year = {2021},
url = {https://arxiv.org/abs/2103.13413},
eprinttype = {arXiv},
eprint = {2103.13413},
timestamp = {Wed, 07 Apr 2021 15:31:46 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-13413.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}